子网的划分和构成超网
目录
- 划分子网
- 使用子网时的分组转发
- 无分类编址CIDR
划分子网
两级IP地址的不合理
IP空间利用率低
一个A类网路可容纳的主机数超过1000W, 而B类网络可容纳主机超过6W.但是有些网络对连接在网络上的主机数量是有限制的, 这就导致了地址空间的利用率低下.
路由表变大导致网络性能低下
给每个物理网络分配一个网络号的话, 会导致路由表中的项目大大增大, 同时查找路由的耗时也就变得更长.
为了解决二级IP带来的问题,从1985年起,将IP地址中增加了一个”子网号字段”, 使得二级IP地址变成三级IP地址.这种做法叫做划分子网.
划分子网的基本思路
- 一个拥有许多物理地址的单位, 可将所属的物理网络划分为多个子网.划分子网属于单位内部的事情,对外还是表现为一个网络.
- 划分子网的方法是从网路的主机号借用若干位作为子网号,于是二级IP地址在单位内部就变成了三级IP地址,即 network-id:subnet-id-host-id
子网划分实例
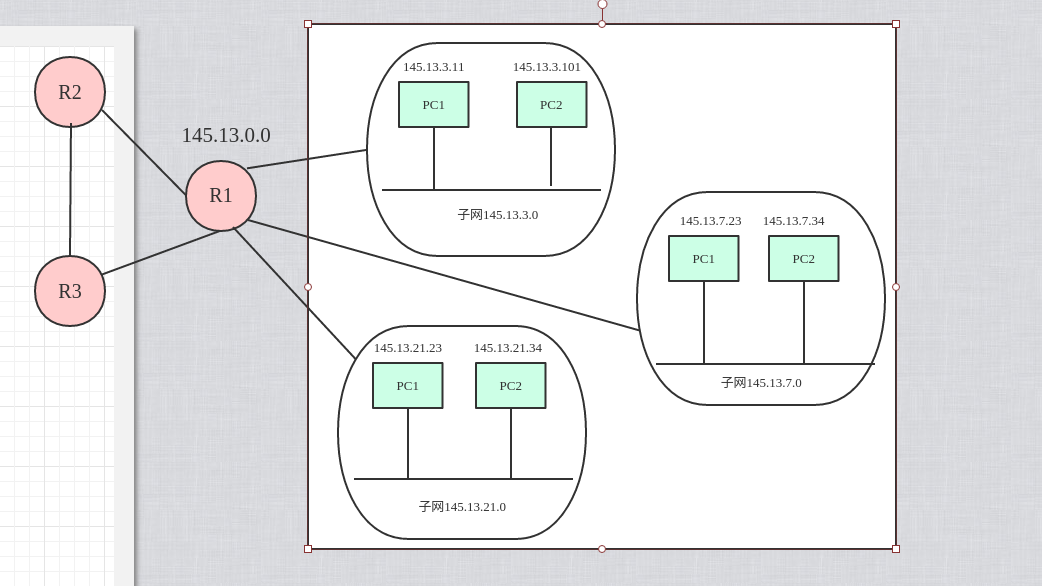
上图的网络被划分为三个子网, 整个网络对外表现为一个网络, 其网络地址为145.13.0.0.但是网络145.13.0.0上的路由器R1在收到外来的数据报后, 再根据数据报的目的地址将它转发到对应的子网.
子网掩码
我们知道, 从IP数据报的首部无法看出源主机或目的主机是否进行了子网的划分,路由器是如何将数据报转发到子网?使用子网掩码可以解决这个问题.
来源
- 子网掩码是一个32位2进制数, 对应的网络地址全为1,主机地址全为0.
- A类网络的默认子网掩码为:255.0.0.0, B类为255.255.0.0, C类为255.255.255.0
通过目的IP地址和子网掩码计算子网的网络地址
- 将数据报的目的IP地址与子网掩码逐位相”与”.
例如: IP地址为141.14.72.24, 子网掩码为255.255.192.0,求网络地址
解析: 子网掩码为11111111 11111111 11000000 00000000, 由于子网掩码的前两个字节的位全为1, 最后一个字节的位全为0,因此, 可暂时推断网络地址为: 141.14.X.0. 此时, 只需要将72对应的二进制数与11000000逐位相”与”,就可得出完整的网络地址: 141.14.64.0.
利用子网数来计算子网掩码
在求子网掩码时, 必须弄清楚划分子网的数目,以及每个子网内所需的主机数目.
1)将子数目转为二进制
2)取得二进制的位数N
3)取得该IP地址的类子网掩码, 将其主机号的前N位置1,即可得该IP地址划分子网的子网掩码
eg: 将B类IP地址168.192.0.0划分为27个子网.
1) 27 = 11011
2) N = 5
3) B类子网掩码: 255.255.0.0
4) 该IP地址划分的子网掩码: 255.255.248.0.
子网的划分选择
下面给出B类子网的划分选择(使用固定的长度子网)
| 子网号位数 | 子网掩码 | 子网数 | 每个子网的主机数 |
|---|---|---|---|
| 2 | 255.255.192.0 | 2^2-2 | 2^14-2 |
| 3 | 255.255.224.0 | 2^3-2 | 2^13-2 |
| 4 | 255.255.240.0 | 2^4-2 | 2^12 -2 |
| 5 | 255.255.248.0 | 2^5-2 | 2^11-2 |
| 6 | 255.255.252.0 | 2^6-2 | 2^10-2 |
| 7 | 255.255.254.0 | 2^7-2 | 2^9-2 |
| 8 | 255.255.255.0 | 2^8-2 | 2^8-2 |
| 9 | 255.255.255.128 | 2^9-2 | 2^7-2 |
| 10 | 255.255.248.192 | 2^10-2 | 2^6-2 |
| 11 | 255.255.252.224 | 2^11-2 | 2^5-2 |
| 12 | 255.255.254.240 | 2^12-2 | 2^4-2 |
| 13 | 255.255.255.248 | 2^13-2 | 2^3-2 |
| 14 | 255.255.255.252 | 2^14-2 | 2^2-2 |
上面-2是因为去掉全0和全1的情况, 子网号位数没有0,1,15,16这四种情况是因为这几种情况没有意义.
使用子网时分组的转发
使用子网划分后, 路由表必须包含这三项内容:目的网络地址,子网掩码和下一跳地址.
路由转发算法
- 从收到的数据报的首部提取目的IP地址D.
- 先判断是否可以直接交付. 对路由器相连的网络逐个检查:用各个网络的子网掩码与D逐位相”与”, 看结果是否和相应的网络地址匹配.若匹配,则把分组直接交付, 否则执行(3).
- 若路由器表中有目的地址为D的特定主机路由, 则把数据报传送给下一跳的路由器,否则执行(4)
- 对路由表中的每一行,用其中的子网掩码和D逐位相”与”,若结果与目的网络地址匹配,把数据报传送下一跳的路由器, 否则执行(5).
- 若路由表中有一个默认的路由, 则把数据报传给默认路由, 否则执行(6)
- 报告转发分组时出错.
转发实例
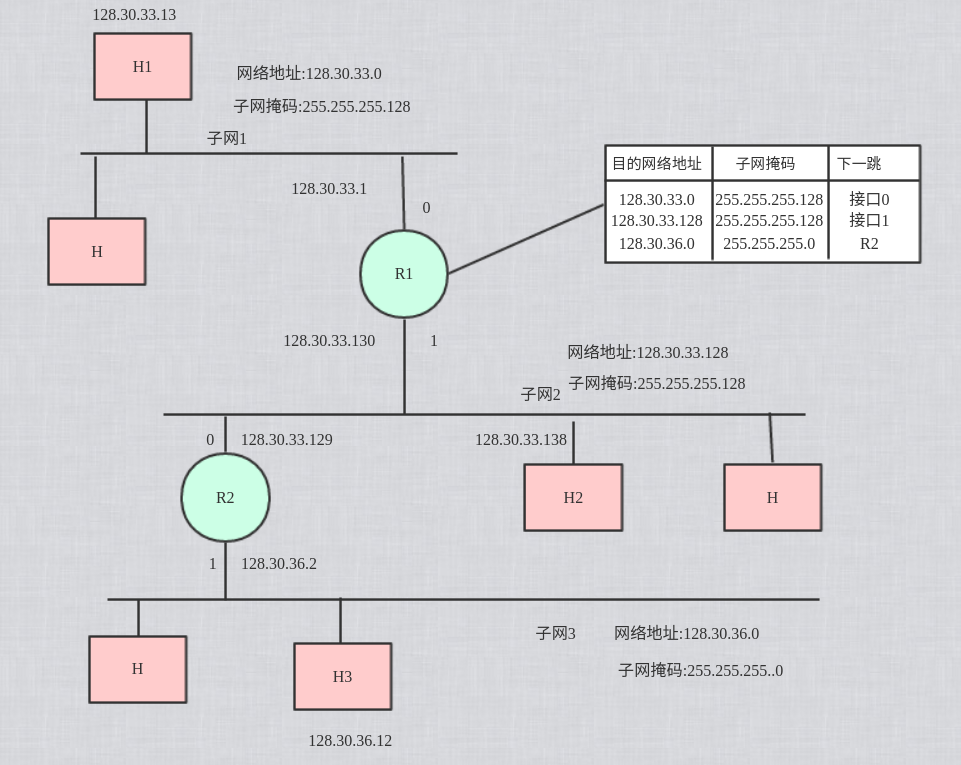
讨论R1收到H1向H2发送分组后,查找路由表的过程
- H1把本子网的子网掩码 255.255.255.128 与目的主机的ip地址逐位相”与”, 得出 128.30.33.128,它不等于H1的网络地址,说明H1与H2不在同一个子网内, 因此H1不能把分组直接交付给H2,必须交给子网上的默认路由器R1,由R1来进行转发
- R1收到一个分组后, 就在路由表中寻找有无匹配的网络地址.(1)计算出目的网络地址为128.30.33.128, 与路由表中的第二行的目的网络地址匹配, 说明这个网络就是分组想要寻找的目的网络, 于是R1将分组从接口1,直接交付给主机H2.
无分类编址CIDR(构成超网)
无分类域间路由选择CIDR解决的问题:
- B类地址眼看就快要分配完了
- 因特网主干网上的路由表项目数急剧增长.
CIDR的两个主要的特点
- CIDR消除了传统的A类,B类,C类地址以及子网的划分的概念,把32位的IP地址划分了两个部分.前一部分用来表示网络前缀,以表示网络. 后一部分则用来表主机.
- CIDR把网络前缀相同的连续IP地址组成一块”CIDR地址块”.
路由聚合
- 由于一个CIDR地址块中有很多地址,所以在路由表中就利用CIDR地址块来查找目的网络. 这种地址的聚合称为路由聚合.
- 它使得一个路由表可以表示更多地址. 路由聚合也称为构成子网.
最长前缀匹配
问题
在使用CIDR时, 由于采用了网络前缀这种记法, 因此在路由表中的项目也要有相应的改变.在查找路由表时, 可能会得到不止一个匹配结果, 那么我们应该选择哪条结果?
最长匹配
为了解决上述问题, 应该从匹配结果中选择具有最长网络前缀的路由, 这叫做最长前缀匹配.
使用二叉线索查找路由表
使用CIDR后, 由于要查找最长前缀匹配, 使路由表的查找过程变得更加复杂.为了更有效的查找, 通常是把无分类编址的路由表存放在一种层次的数据结构中, 然后,自上而下进行查找.这里最常用的是二叉线索.为了提高二叉线索的查找速度,可以使用压缩技术.
参考资料